
OpenAI признала, что ИИ-браузеры вряд ли когда-нибудь станут полностью защищёнными от атак с внедрением промптов — приёмов, при которых злоумышленники прячут вредоносные инструкции в тексте писем или веб-страниц. В компании сравнивают эту угрозу с фишингом и социальной инженерией: полностью устранить её невозможно — можно лишь снижать риски.

Поводом для заявления стало развитие браузера ChatGPT Atlas, запущенного в октябре этого года. Независимые исследователи быстро показали, что скрытые инструкции, например в Google Docs или письмах, способны менять поведение ИИ-агента. OpenAI признаёт, что «агентный режим» расширяет поверхность атаки, и с этим согласны другие участники рынка: от создателей браузера Brave до британского Национального центра кибербезопасности, который прямо заявил, что такие атаки «могут никогда не быть полностью устранены».
[my_slider id="1"]
Со своей стороны OpenAI делает ставку на многоуровневую защиту и быстрые обновления, а также использует необычный подход — собственного «автоматического атакующего». Это ИИ, обученный с подкреплением, который играет роль хакера: он ищет уязвимости, тестирует атаки в симуляции, анализирует реакцию системы и снова пробует. По словам компании, такой метод позволяет находить новые сценарии атак быстрее, чем это сделали бы реальные злоумышленники.
При этом эксперты призывают к осторожности: ИИ-браузеры получают доступ к почте, платежам и аккаунтам, что делает их особенно чувствительными к ошибкам. OpenAI советует ограничивать доступ агентов к личным данным, требовать подтверждение важных действий и давать им чёткие инструкции вместо «делай всё сам».
 ChatGPT теперь лучше понимает и поддерживает людей в кризисных ситуациях
ChatGPT теперь лучше понимает и поддерживает людей в кризисных ситуациях 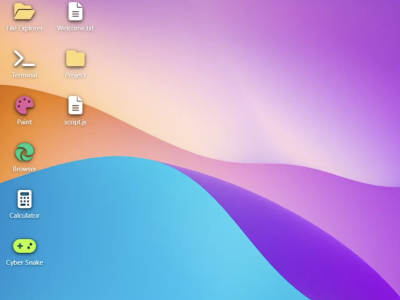 В Gemini 3.1 Pro создали клон интерфейса Windows 11 с помощью одного запроса
В Gemini 3.1 Pro создали клон интерфейса Windows 11 с помощью одного запроса 



Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: